How to stop slouching
Posted on 19 Kasım 2018 in Kişisel by admin
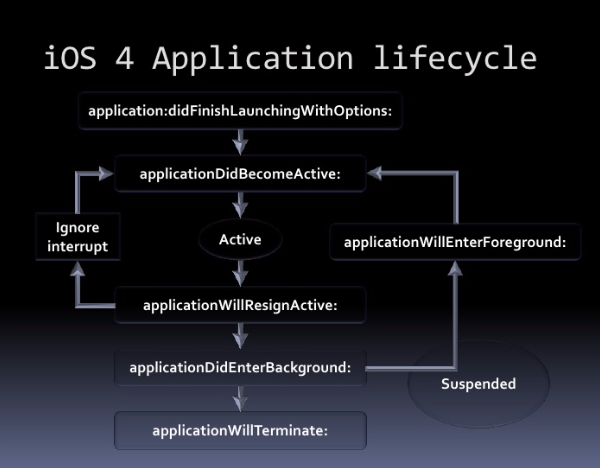
Application life cycle
Posted on 08 Kasım 2018 in Programlama by admin
Application states could be briefly described as below:
Design patterns
Posted on 06 Kasım 2018 in Programlama by admin
https://sourcemaking.com/design_patterns/
IOS Pushkit integration
Posted on 06 Kasım 2018 in Programlama by admin
Necessary tools:
https://github.com/noodlewerk/NWPusher
How to make a c++ class singleton easily
Posted on 06 Kasım 2018 in Programlama by admin
https://sourcemaking.com/design_patterns/to_kill_a_singleton
Refactoring singleton usage in Swift
Posted on 06 Kasım 2018 in Programlama by admin
In this post, it is explained how to properly use of singleton in view controllers. It basically uses dependency injection on singleton instances.
https://www.jessesquires.com/blog/refactoring-singletons-in-swift/
IOS introduction to delegates
Posted on 04 Kasım 2018 in Programlama by admin
Concurrent vs serial queues in GCD
Posted on 03 Kasım 2018 in Programlama by admin
There is a good conversation here
https://stackoverflow.com/questions/19179358/concurrent-vs-serial-queues-in-gcd
An example to running sync call and async queue. Sync task in a different queue blocks current caller thread.
You have two guys – Bob and Mark. Bob makes dough and gives it to Mark to put in the oven. And here you can have two scenarios, either Bob will wait with making next batch of dough until Mark puts current batch in the oven (this would be sync) or he will start right away and won’t bother if Mark did his job already (async)
It may sound like sync does not make sense – what’s the point of concurrency if you have to wait for other thread to finish its work? But actually it has some valid applications. As you know, all UI calls need to be performed on main thread. Let’s assume you have some code which runs in background queue and from time to time it needs to check if app is in the background or foreground. It can be done by asking UIApplication for applicationState, yet calling it from background thread might cause crash or at least a threading warning. So the solution is:
let applicationState = DispatchQueue.main.sync { return UIApplication.shared.applicationState }
This will block current queue until main queue returns this value. You can’t use async here as you need this value to continue your work. Analogy for Bob and Mark would be waiting for Mark to tell Bob if there is still space in the oven for next batch of cake, so Bob can decide if he should make it or not 😉
Finding top view controller in swift
Posted on 11 Ekim 2018 in Programlama by admin
How to find visible view controller?
func topMostController() -> UIViewController {
var topController = UIApplication.shared.keyWindow?.rootViewController
while (topController?.presentedViewController != nil) {
topController = topController?.presentedViewController
}
return topController!
}
func topViewController(_ controller: UIViewController? = UIApplication.shared.keyWindow?.rootViewController) -> UIViewController? {
if let navigationController = controller as? UINavigationController {
return topViewController(navigationController.visibleViewController)
}
if let tabController = controller as? UITabBarController {
if let selected = tabController.selectedViewController {
return topViewController(selected)
}
}
if let presented = controller?.presentedViewController {
return topViewController(presented)
}
return controller
}
class Singleton {
static var shared = Singleton()
private let internalQueue = DispatchQueue(label: "SingletionInternalQueue", qos: .default, attributes: .concurrent)
private var _foo: String = "aaa"
var foo: String {
get {
return internalQueue.sync { _foo }
}
set (newState) {
internalQueue.async(flags: .barrier) { self._foo = newState }
}
}
func setup(string: String) {
foo = string
}
}
Thread safety is accomplished by having a computed property foo which uses an internalQueue to access the “real” _foo property.
Also, in order to have better performance internalQueue is created as concurrent. And it means that it is needed to add the barrier flag when writing to the property.
What the barrier flag does is to ensure that the work item will be executed when all previously scheduled work items on the queue have finished.
https://stackoverflow.com/questions/49160125/thread-safe-singleton-in-swift
